Конфигурирование сервера Oracle для сверхбольших баз данных
Восстановление инстанции сервера Oracle
Длительность времени, необходимая для выполнения восстановления инстанции сервера Oracle является важным параметром для архитектора VLDB, поскольку она определяет период, в течение которого приложение будет недоступно после возникновения следующих событий:
- Отказ узла без кластера — отказ процессора, шины или памяти на незащищенном с помощью кластера узле.
- Отказ узла параллельного сервера Oracle — отказ одного или нескольких узлов в конфигурации с параллельным сервером Oracle будет причиной кратковременной недоступности всего кластера, которая оканчивается к моменту, когда «выжившие» узлы завершат восстановление нитей отказавших узлов.
Реализация отложенного, «по требованию», отката в Oracle 7.3 делает период недоступности кластера зависящим, в основном, от времени которое необходимо для реконструкции буферного кэша. Диаграмма, сравнивающая время восстановления после отказа в Oracle 7.3 и Oracle 7.2, приведена на рисунке 2.
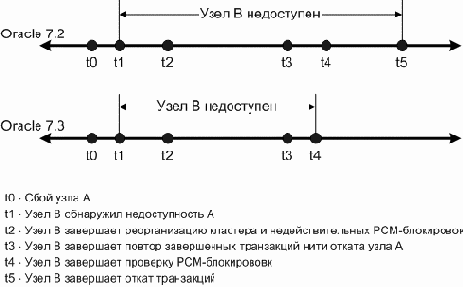
Рис. 2.Временная диаграмма восстановления после отказа для параллельного сервера Oracle 7.2 и 7.3. OPS 7.3 откладывает откат транзакций для минимизации периода недоступности кластера при отказе узла, что дает улучшение производительности восстановления по сравнению с OPS 7.2 или ниже. В OPS 7.3 время завершения отката инстанции не связано с доступностью приложений, поскольку все откаты запускаются «по требованию», на уровне транзакций.
Восстановление инстанции сервера Oracle — настраиваемый процесс, время выполнения которого, в основном, зависит от двух факторов [, Maulik and Patkar (1995)]:
- Объем повторно-применяемой информации (redo-информации), которая была сгенерирована с момента последней контрольной точки (чем меньше, тем лучше), и
- Качество буферного кэша базы данных в течение выполнения восстановления (чем выше, тем лучше).
На первый фактор, в основном, влияет скорость генерации redo-информации и частота выполнения контрольных точек. Уменьшение объема генерируемой redo-информации является задачей разработчика приложения и связано с минимизацией «веса» транзакций, минимизацией числа транзакций, необходимых для достижения требований бизнеса и использованием там, где это допустимо, режима работы без восстановления. Уменьшение частоты выполнения контрольных точек достигается изменением параметра, определяющего интервал между контрольным точками или, возможно, увеличением размера журнального файла.
Улучшения, относящиеся ко второму фактору, Вы можете достичь с помощью увеличения размера буферного кэша базы данных и уменьшения, тем самым, вероятности промахов в буферном кэше в течение выполнения процедуры восстановления. Увеличение значение параметра db_block_buffers для работы процесса восстановления (ценой уменьшения значения параметра shared_pool_size, если необходимо) в общем, уменьшает число промахов в буферном кэше. В течение процедуры восстановления, при котором не требуется выполнения восстановления носителя, Вы не имеете других способов влиять на процент попаданий в буферный кэш, поскольку должна быть повторно применена вся информация, которая была сгенерирована с момента последней контрольной точки .
Меняя параметр log_checkpoint_interval в диапазоне от нескольких килобайт до нескольких сотен мегабайт (в блоках операционной системы) можно достичь приемлемого компромисса с производительностью в OLTP-среде. Скорость доката при восстановлении варьируется почти также как кардинально, как и требования к скорости доката . В средах с жестко заданными требованиями к производительности и надежности малое изменение log_checkpoint_interval может привести к значительному изменению времени восстановления инстанции. Вследствие этого поиск оптимального значения log_checkpoint_interval
часто требует тестирования в среде эксплуатации.